用知识战疫,清华大学开放“文泉学堂”知识库,全国师生可免费使用。
机械工业出版社前日也开放了一批电子书,但无论质量还是数量上都没有清华的好(清华出版社IT类书籍有一万余册)
前去翻了翻文泉学堂开放的2019和2018年的IT类电子书,有几本很值得看,但是在线读不太方便,而且不知哪天会关闭免费阅读通道。所以想着批量下载下来慢慢看。
打开chrome控制台暗中观察:每一页实际是单张的jpg图片,图片的链接是一个形如 /page/img/${bookId}/${pageNum}?k=${token}的url,最初单纯的以为一个token可以用来重复下载一本书中的每一页,但其实不能,用来加载每一页的token后半部分不同。
那么如何得到token就是解决批量下载图片问题的关键所在。
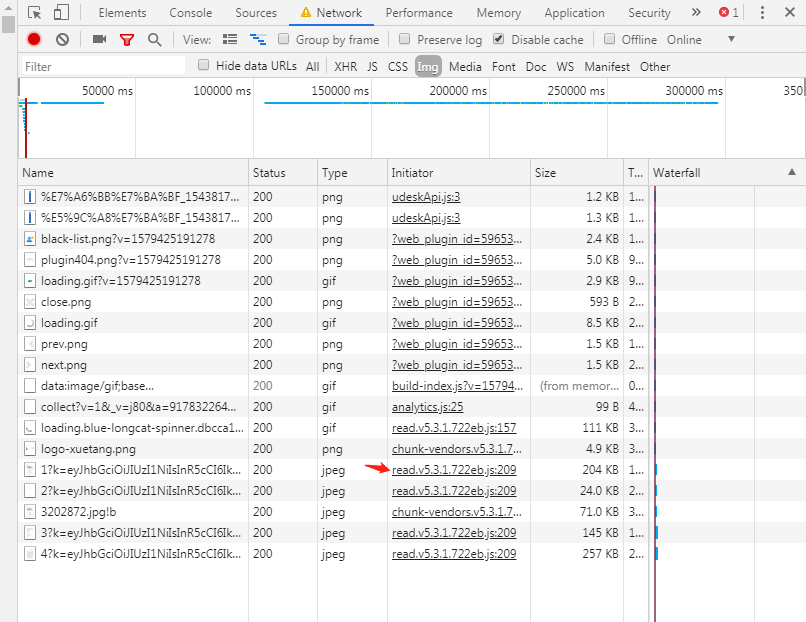
再查,发现token不是由ajax从服务端获取的,而是js生成的(因为没有额外的网络请求)。在chrome控制台中看到图片的加载是由 read.v5.3.1.722eb.js 触发的。检查这个js的源码,应该是打包工具编译混淆后的产物,代码被uglify为一行。使用代码格式化工具还原为多行,可读性依然很差,很多例如e, t, r之类的变量名。
搜索关键词“k=”,只有两处,幸而发现很多方法名没有被混淆,一个名为getJwt的方法映入眼帘,这个方法明显参与了图片路径的构造环节,应是解决问题的关键。getJwt的第一个形参应该是书籍ID,第二个形参应该是页码数。
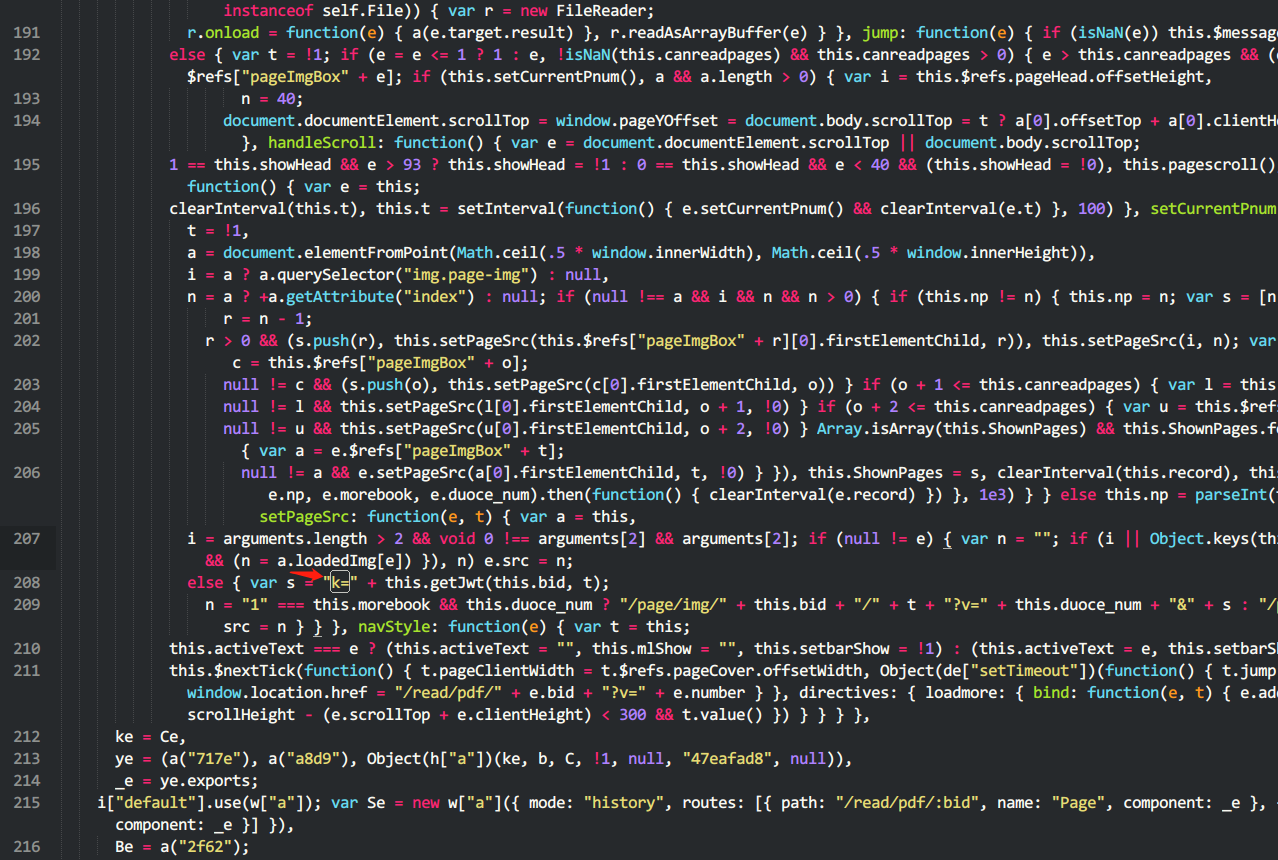
找到这个方法被定义的位置,很容易的将方法暴露到window对象上(红框位置是增加的唯一一处代码)。
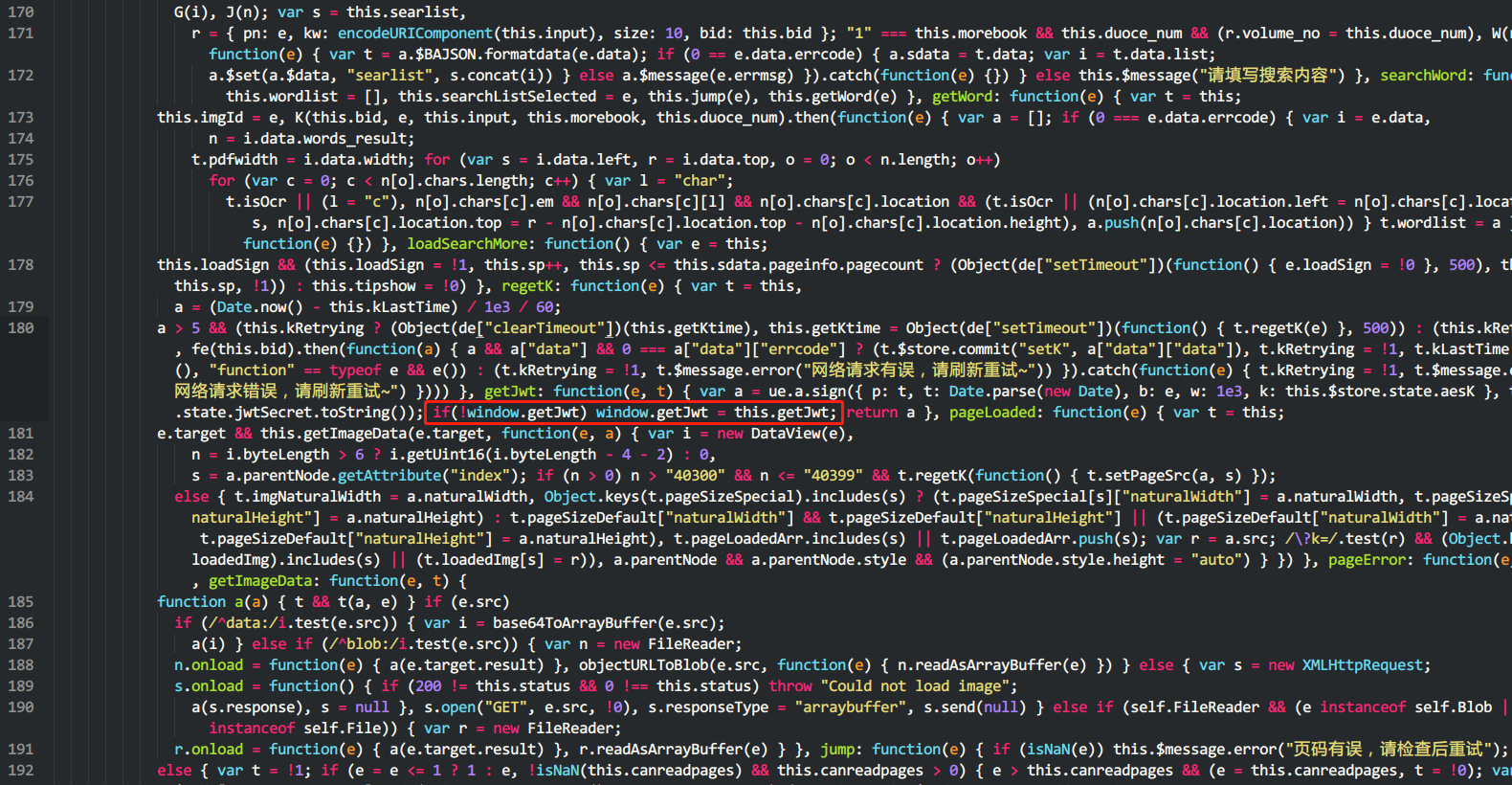
将魔法改装后的read.js文件利用chrome的overrides功能(chrome真的太强大了!),覆盖源站的read.v5.3.1.722eb.js(此处略,网上有很多关于overrides的介绍),让浏览器在加载页面时使用本地魔改的read.js资源而不从远程站点获取。
再辅以如下js脚本(看到想要的书,在控制台中录入),轻松获得一本书的全部篇数,一页不漏。
1 | async function download() { |
得到全书高清晰度jpg格式图片,最后再借助例如foxit phantomPDF软件,将所有图片批量合成为单个pdf。留着慢慢阅读吧。
本文提到的爬虫技术仅供参考,切勿整站爬取,整站爬取不道德。

